
















Serverless CI/CD Pipelines: Pros, Cons, and Real Use Cases
As companies continue to chase faster delivery and effortless scalability, the idea of Serverless CI/CD pipelines is changing how teams think about software delivery. Instead of worrying about managing build servers or scaling runners, serverless lets you focus purely on the code and automation. It brings flexibility, auto-scaling, and cost savings — but it’s not all smooth sailing. Debugging, cold starts, and cloud lock-in can still make things tricky. In this blog, we’ll break down the real pros, cons, and actual use cases of serverless CI/CD, and explore how it’s quietly reshaping the future of DevOps.

Introduction: The Evolution of CI/CD
A few years back, setting up CI/CD meant maintaining Jenkins servers, managing runners, and praying that the build agents didn’t die mid-deployment.
If you’ve ever SSH’d into a CI node at 2 AM to restart a stuck pipeline, you know the pain.
That’s where Serverless CI/CD quietly changes the game.
You don’t babysit servers anymore — you just define the pipeline, and your cloud provider handles the heavy lifting.
GitHub Actions, AWS CodePipeline, and Google Cloud Build are making CI/CD almost feel… invisible.
Think of it like this — you write YAML, push code, and watch the magic happen. No infra tickets, no patching, no idle costs.
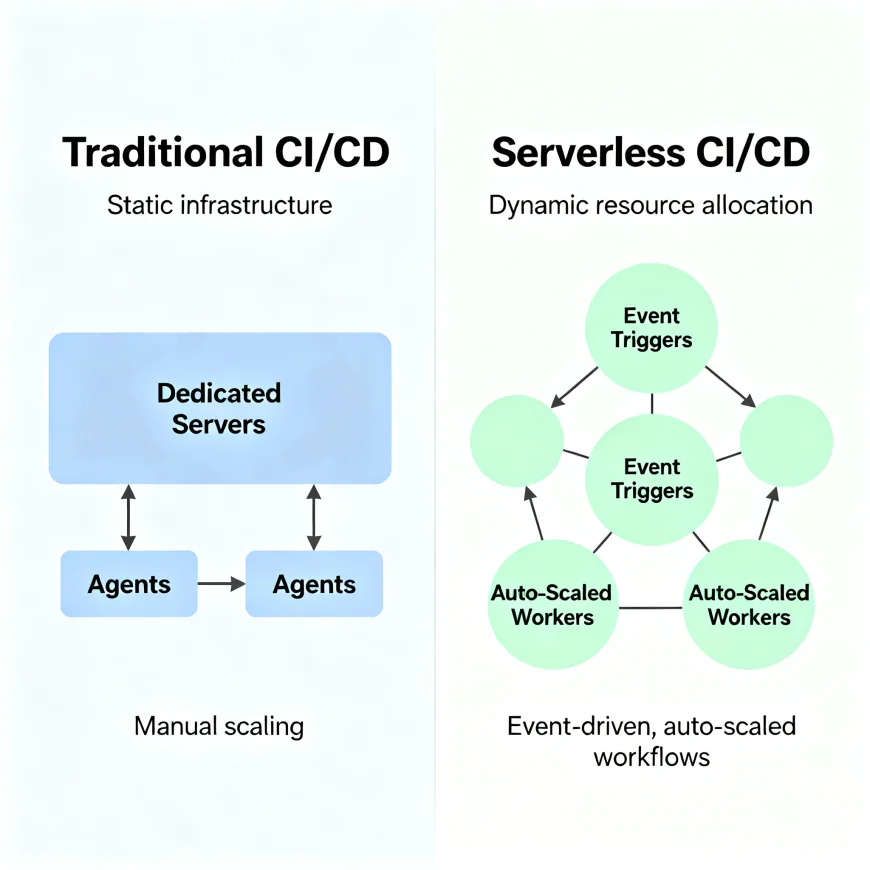
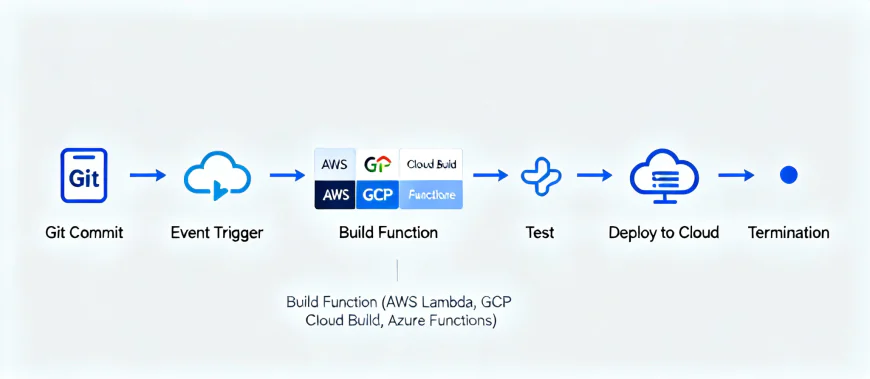
How Serverless CI/CD Works
Instead of running on a persistent machine, everything runs on-demand.
When a developer pushes code:
- A webhook triggers a build event.
- A short-lived container (or function) spins up.
- It runs your build/test/deploy tasks.
- The environment disappears once done — zero cleanup.
No long-running VMs, no idle agents eating your budget.
Everything is event-driven and ephemeral, which is exactly what DevOps has always wanted.
Key Advantages of Serverless CI/CD
1. No Infra maintenance
No patching, scaling, or dependency chaos. The CI/CD just works.
2. Cost control
You pay only when builds run. Ideal for startups and side projects that can’t justify 24×7 build servers.
3. Scales without complaining
Whether you run 5 builds or 500, the cloud scales for you automatically.
4. Isolated & Secure
Each build runs in its own container — no cross-contamination or leaked credentials.
5. Plays nice with multi-cloud
You can mix tools — GitHub Actions triggering AWS Lambda deploys or GCP builds deploying to Azure.

Challenges and Limitations
While appealing, serverless CI/CD isn’t a silver bullet.
1. Cold Start Latency
If a function hasn’t run in a while, it takes a few seconds to start. Not fun when you’re waiting on feedback loops.
2. Limited Execution Time
Most serverless functions cap out at 15 minutes. Long integration tests won’t fit in that window.
3. Debugging Complexity
No persistent machine means you can’t just ‘SSH and tail logs.’ You rely heavily on cloud logs.
4. Vendor Lock-in
Using proprietary services like AWS CodeBuild or Google Cloud Build tightly couples your pipeline with one cloud ecosystem.
Real-World Use Cases
1. Lightweight Microservice Deployments
Each microservice build can trigger a dedicated serverless workflow. Ideal for microservice-heavy environments like Netflix or Shopify.
2. Event-Driven Deployments
Deploy when a Docker image is pushed or a config file changes.
Completely automated and auditable.
3. Security Scanning Pipelines
Run quick container scans (using Trivy or Grype) in an isolated job right before production.
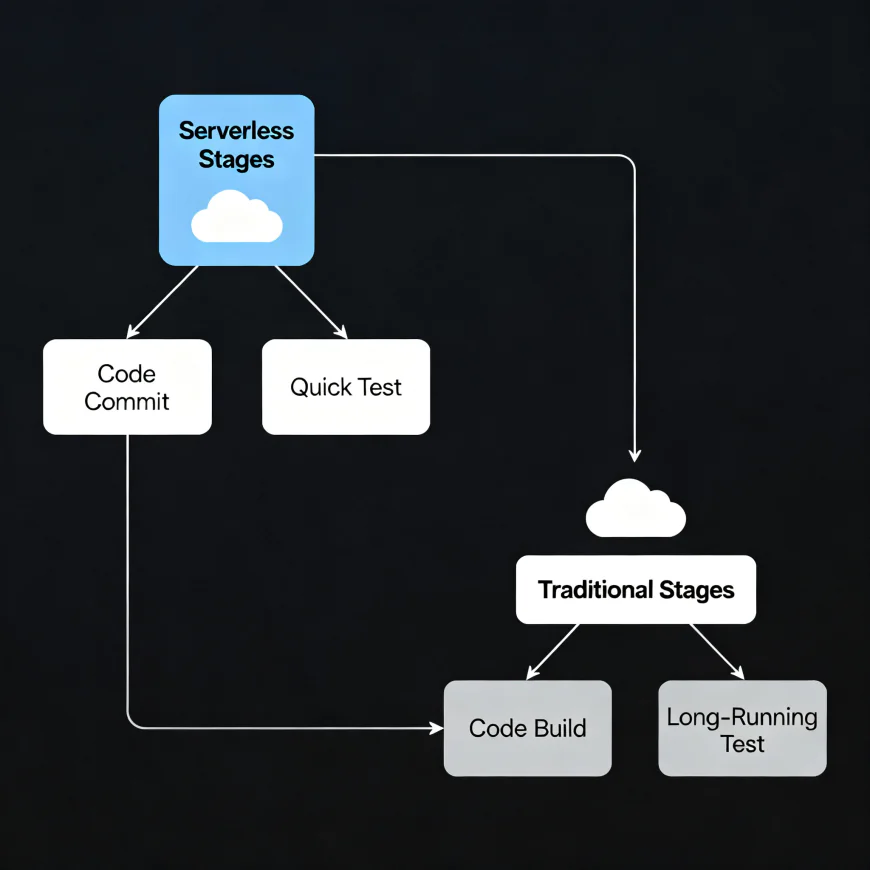
4. Hybrid Pipelines
Run lightweight stages in serverless and keep longer tests on persistent runners — best of both worlds.
Use serverless stages for lightweight tasks and persistent servers for long integration tests.
Popular Tools You’ll See in Action
|
Category |
Tool |
Why It’s Useful |
|
Cloud CI/CD |
AWS CodeBuild, Google Cloud Build |
Fully managed, scalable, integrates deeply with cloud |
|
Git Automation |
GitHub Actions, GitLab CI |
Event-driven, YAML-based, and super customizable |
|
Custom Serverless |
Tekton, Jenkins X |
Kubernetes-native, great for large orgs |
|
Security & Provenance |
Sigstore, OPA |
Helps verify supply chain integrity |
Best Practices
- Use caching (e.g., S3, Artifact Registry) to reduce cold start impact.
- Separate pipelines by task type (build, test, deploy).
- Integrate FinOps checks to avoid cost overruns.
- Ensure immutability of build environments.
- Use infrastructure as code (IaC) to define pipeline components declaratively.
Conclusion
Serverless CI/CD is not just a cost-cutting trend — it’s a fundamental shift toward automation-driven, elastic DevOps practices. By combining serverless compute with event-based orchestration, teams achieve faster releases, simplified operations, and scalable pipelines. However, successful adoption demands balancing control with convenience — knowing when to go serverless and when not to.