
















AWS Outage of October 2025: How a DNS Failure Brought the Internet to a Standstill
The October 2025 AWS outage was caused by a DNS failure in its US-EAST-1 region, disrupting thousands of websites and apps globally for several hours. Major platforms like Snapchat, Fortnite, and Coinbase were affected, exposing how dependent the internet is on AWS’s infrastructure. AWS resolved the issue within the day, but the event highlighted risks of centralized cloud reliance and the need for better resilience strategies.

October 20, 2025, was the day that Amazon Web Services (AWS)—the backbone to much of the modern internet—suffered an outage that was one of its biggest and most disruptive ones in years. Over the outage, there were mixed feelings; some considered it a signal of warnings about the current situation with cloud infrastructure where the major portion of the workload was done on the centralized systems while others saw it as a problem needing solutions.
The Outage: What Exactly Happened
What Happened On October 20 at around 12:11 AM Pacific Time, the first signs of AWS outage were reported in the US-EAST-1 Availability Zone, the largest and most critical data center of AWS in Northern Virginia. The chain reaction of outages and connectivity problems majorly affected global internet services within minutes of the incident.
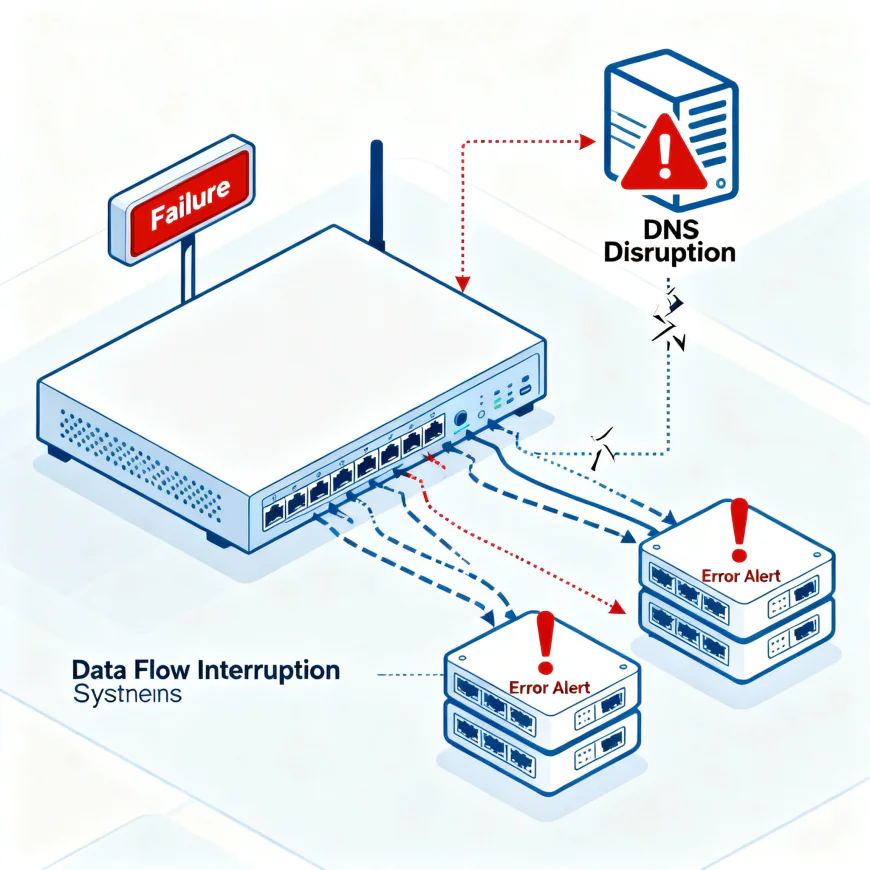
At that time, the core issue was a failure in Amazon’s internal Domain Name System (DNS)— the system that converts website URLs into the location's numeric IP addresses so that computers can find one another. A failure in a subsystem that was responsible for network load balancer health checks was concluded to have led to DNS records' corruption and connection blockage to Amazon DynamoDB's API endpoints by AWS's engineers. Consequently, a host of AWS services depending on the internal DNS and connections to the AWS databases (EC2, Lambda, S3, CloudFormation, etc.) were hit by a string of failures at the same time.
The shutdown was not contained to the internal services alone. A large number of the cloud workloads were working on AWS's internal networking backbone, and hence, a number of the AWS services in other Regions of AWS suffered performance degradation or latency while the issue was being sorted out.

Think about the scale of the effect
The AWS outage has been claimed to have an impact on over 2,500 world-wide companies and services. The varied affected services denote the intimate binding of AWS into the everyday and digital life on the globe.
The consequences were significant, such as:
Social media and communication: The entire outage of Snapchat, WhatsApp, Reddit, and Signal cut off millions of users from enjoying the service or sending or reading new messages.
Streaming and entertainment: Disney+, Amazon Prime Video, and Canva were among the heavily affected.
Finance and retail: Payment systems came to a standstill with the down of Coinbase and Robinhood apps along with many others, thus making it impossible to carry out a transaction.
Gaming: The Epic Games' Fortnite and Roblox servers were among those getting impacted by periods of disruption and millions of dissatisfied users.
IoT and smart home: Users could not control or operate their home appliances because Amazon's Alexa and Ring cameras were down.
Education and government: The major breakdown of the HMRC tax portal and Canvas LMS areas temporarily disabled countless academic services from the UK.
One may suggest that mission-critical services such as EHRs (Electronic Health Record systems) and logistics tracking APIs might also have faced interruptions along with the disruptions to service continuity, thus uncovering the potential vulnerabilities of the cloud-based uptime.
The Technical Cause for the Outages
If we look at it from an engineering standpoint, the outages can practically be dubbed a DNS resolution failure resulting from the improper functioning of the AWS control plane's Network Load Balancer (NLB) subsystem.
The internal DNS system of AWS facilitates the communication of the resources in the cloud such as the EC2 instances, DynamoDB tables, and S3 buckets in a controlled manner through an internal endpoint. If the NLB subsystem is defective, then the health checks won’t be updated correctly, which misinforms that some of the backend servers are still operational. It can wrongly mark the servers as "offline" even when they are still online, resulting in an invalid DNS lookup. Consequently, every internal service DNS resolution gets disabled, which in turn results in a failure cascade throughout inter-service communications, as things can no longer be resolved.
Moreover, since several major AWS services such as Lambda (a serverless compute service) and S3 (an object storage service) are also dependent on DynamoDB for configuration and deployment state maintenance, failure in internal lookups leads to propagation of the outage through the control plane by halting automation workflows, stopping deployments, and breaking functionality for real-time applications.
When considering this, it was a fundamental systemic failure that was underneath: the dependencies of the multi-service that AWS has are so interconnected that a single failure in one subsystem can cause successive failures throughout the whole AWS global network infrastructure. Consequently, this was not a security issue nor an external hacking, but a design flaw that was enlarged and brought to light the design flaws they had crafted.
Recovery Efforts
Within the first 2 hours of the incident, AWS’s Network Operations Center (NOC) traced the origin of failure. Engineers began to identify the erroneous health check nodes and replumb the requests through unaffected network traffic. By about 8:00 AM PDT, DNS systems had been mostly recovered and services largely returned to service and operational.
However, due to the tumbled queue in the asynchronous tasks (e.g., there was large backlogs of queued emails and API requests, as well queues on writes to databases) to those asynchronous tasks, customers remained experience delays on those functionalities into the afternoon hours.
AWS issued a preliminary post-incident report the following day, confirming the issue's cause and outlining plans to increase redundancy in its internal DNS resolution paths. The company also committed to adding region-level DNS fallback capabilities to allow dependent services to temporarily use alternative regions during localized outages.
Industry Reaction: The Perils of Centralization
The AWS outage revived long-standing discussions regarding cloud dependencies and centralization on the internet. With over 30% of the total digital workloads globally running on AWS, even minor service interruptions can have real economic ripples.
Tech industry watchers likened the accident to a "digital blackout." For both startups and enterprises, the downtime provided a sobering reminder that even the most reputable infrastructure can be impacted by an event that takes down systems at the same time.
Financial analysts estimated the outage incurred losses that could go above $550 million in delays in global productivity for e-commerce platforms, fintech apps,, and online advertising platforms that all experienced downtime.
Many believe the outage will push enterprises toward multi-cloud strategies — to distribute workloads across AWS, Google Cloud Platform (GCP), and Microsoft Azure — as a means to minimize risk. Others see the opportunity to invest in edge computing and hybrid-cloud architectures to ensure mission-critical operations can continue offline during an outage incident.
Lessons Learned: Considerations for Businesses
For developers, administrators, and cybersecurity teams, the AWS outages in October 2025 teach important lessons.
Implement Redundant Architectures:
Have a multi-region failover plan. By replicating your applications (with a proper architecture like microservices) and databases across at least two AWS regions it will allow for more available applications when localized outages occur.
Invest in DNS Freedom:
It is risky to rely on only AWS’s internal DNS as a resource for your application services. Having pathways to use external DNS resources such as Cloudflare or Google DNS allow your application to remain operational when AWS’s internal network fails.
Utilize Health Checks and Circuit Breakers:
For communication between services ensure you have enabled observability tools to watch for errors or degraded service. Use circuit breaker patterns to prevent a total collapse in achieving service functionality when backend dependencies return errors or fail.
Keep Track of Vendor Dependancies:
Even SaaS and PaaS tools can rely on AWS under the hood. Monitor vendor SLAs and determine if critical vendors to your operations can survive a planned outage.
Revise Your Incident Response Plans:
Your disaster recovery playbook should include clear accountabilities for communications to stakeholders and customers. The automation of portions of the recovery process (e.g., routing failover and status reporting) can greatly reduce the overall impact to downtime.
Consider on Edge Data Processing or Data Processing Locally:
Having decentralized or edge-based architectures that can fulfill some critical function locally will provide value when your cloud backend is down. This has more of an impact for IoT and industrial automation use-cases.
Wider Consequences: A Delicate Internet
Outside of the operational aspects, this incident highlights a growing systemic issue—with the internet’s reliance on a few scale providers. AWS, Google Cloud, and Azure own the vast majority of the world’s server infrastructure. As illustrated here, a single misconfiguration can lead to a cascading failure that runs across millions of systems interconnected.
The post-outage analysis shows that during the six-hour period, nearly 38% percent of global online traffic were experiencing latency or could not be reached at all. This was not just web applications, but DNS resolvers, identity management and authentication, APIs, and various interconnected systems collectively making up the digital supply chain.
Finally, security practitioners have noted that misconfigurations like these could serve as dry runs for how future cyberattacks might leverage cloud centralization. In the event that rogue actors were to compromise a command and control subsystem similar to the one that experienced a misconfiguration here, the consequences will exceed temporary interruptions in service.

AWS's Response and their Promises
On October 21, AWS announced that full service was restored and, in a series of corrective steps, made the following commitments:
The expansion of clusters of redundant DNS resolvers in all major regions.
Automated self-healing and rollback mechanisms for the network health checks.
The rollout of new dashboards for transparency to customers to improve visibility and communication during outages.
A long-ranging commitment to decouple dependence on only critical AWS infrastructure components from a single region.
While AWS’s initiatives are prospective acts to regain trust, they may not be sufficient given the customers that demand more visibility into how the infrastructure works and how to prevent failures. With enterprises continuing the move to the cloud, AWS’s “always-on” reputation could take months to restore trust.
Conclusion
The AWS outage in October 2025 exposed not a mere failure in technology but a structural weakness about how modern internet technology works. As so much of the daily experience is dependent on a handful of centralized providers, including social networking, even small misconfigurations can cause global scale impact.
For developers, IT professionals, and businesses, the most important realization is preparedness. Redundancy, observability, and multi-cloud resilience are no longer extravagant or ‘nice to have’ ideas, instead they are now a matter of survival. Cloud computing may have enabled us to connect, without thoughtful planning, resilient behavior of our systems must be developed at the same pace as convenience.